
K Means Clustering

What is K-means Clustering?
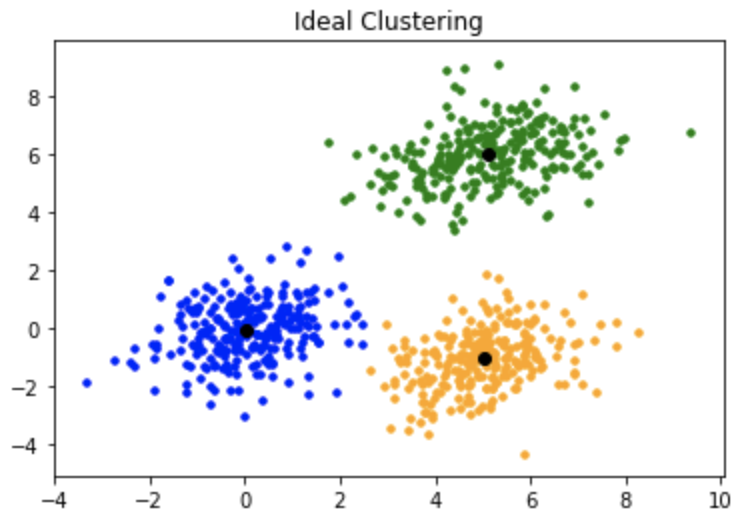
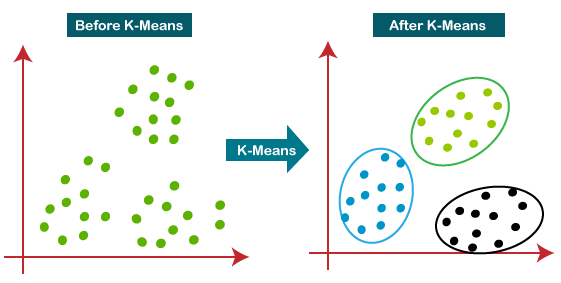
K-means is a centroid-based algorithm, or a distance-based algorithm, where we calculate the distances to assign a point to a cluster. In K-Means, each cluster is associated with a centroid.
Applications of Clustering
Clustering has a large no. of applications spread across various domains. Some of the most popular applications of clustering are:
- Recommendation engines
- Market segmentation
- Social network analysis
- Search result grouping
- Medical imaging
- Image segmentation
- Anomaly detection
K-Means using Numpy:
import io
import pandas as pd
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
import numpy as np
df2 = pd.read_csv(io.BytesIO(uploaded['dataset_3.csv']))
data = df2.values
print(data)
def normalize(data):
return (data - data.min(axis=0))/(data.max(axis=0)-data.min(axis=0))
data = normalize(data)
plt.plot(data[:,0],data[:,1],'.')
means = np.random.random((3,2))
plt.plot(data[:,0],data[:,1],'.')
plt.plot(means[0,0],means[0,1],'ro')
plt.plot(means[1,0],means[1,1],'go')
plt.show()
for i in range(5):
labels = cdist(data,means).argmin(axis=1)
for k in range (3):
dataset = data[labels == k]
plt.plot(dataset[:,0],dataset[:,1],'.')
means[k] = dataset.mean(axis=0)
plt.plot(means[k][0],means[k][1],'X')
plt.show()
K-Means using Scikit Learn:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
plt.scatter(X[:,0], X[:,1])

wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()

kmeans = KMeans(n_clusters=4, init='k-means++', max_iter=300, n_init=10, random_state=0)
pred_y = kmeans.fit_predict(X)
plt.scatter(X[:,0], X[:,1])
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red')
plt.show()






No comments
If you have any doubts, Please let me know