
PCA (Principal Component Analysis) using sklearn

For a lot of machine learning applications, it helps to be able to visualize your data. Visualizing 2 or 3-dimensional data is not that challenging. You can use PCA to reduce that 4-dimensional data into 2 or 3 dimensions so that you can plot and hopefully understand the data better.
Steps for the PCA:
1. load the data
2. standardize the data
from sklearn.preprocessing import StandardScaler
features = ['sepal length', 'sepal width', 'petal length', 'petal width']# Separating out the features
x = df.loc[:, features].values# Separating out the target
y = df.loc[:,['target']].values# Standardizing the features
x = StandardScaler().fit_transform(x)
3. Import PCA and build model:
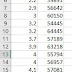
from sklearn.decomposition import PCApca = PCA(n_components=2)principalComponents = pca.fit_transform(x)principalDf = pd.DataFrame(data = principalComponents
, columns = ['principal component 1', 'principal component 2'])principalDf.head()
# Concatenate the clusters labels to the dataframepca_df = pd.concat([principalDf, pd.DataFram({'cluster':Features})], axis = 1)

Collab Link: Click Here




No comments
If you have any doubts, Please let me know