
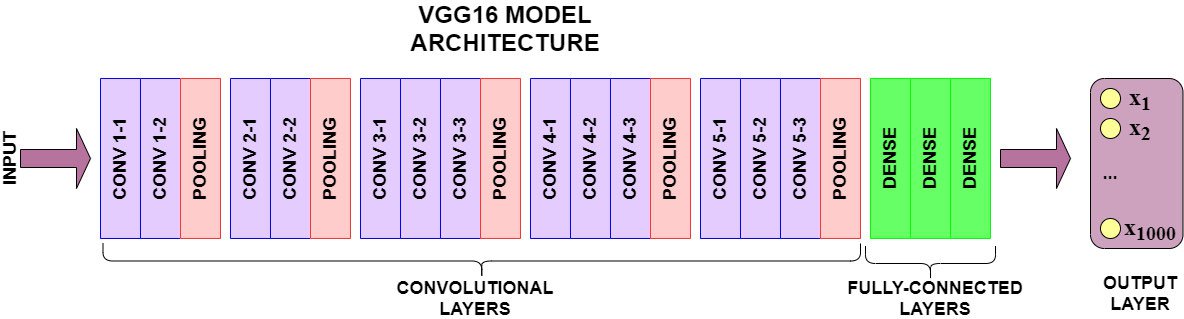
Classification using Transfer Learning(VGG16)

VGG16:
VGG16 is a convolutional neural network trained on a subset of the ImageNet dataset, a collection of over 14 million images belonging to 22,000 categories. K. Simonyan and A. Zisserman proposed this model in the 2015 paper, Very Deep Convolutional Networks for Large-Scale Image Recognition.
In the 2014 ImageNet Classification Challenge, VGG16 achieved a 92.7% classification accuracy. But more importantly, it has been trained on millions of images. Its pre-trained architecture can detect generic visual features present in our Food dataset.
Now suppose we have many images of two kinds of cars: Ferrari sports cars and Audi passenger cars. We want to generate a model that can classify an image as one of the two classes. Writing our own CNN is not an option since we do not have a dataset sufficient in size. Here's where Transfer Learning comes to the rescue!
We know that the ImageNet dataset contains images of different vehicles (sports cars, pick-up trucks, minivans, etc.). We can import a model that has been pre-trained on the ImageNet dataset and use its pre-trained layers for feature extraction.
Now we can't use the entirety of the pre-trained model's architecture. The Fully-Connected layer generates 1,000 different output labels, whereas our Target Dataset has only two classes for prediction. So we'll import a pre-trained model like VGG16, but "cut off" the Fully-Connected layer - also called the "top" model.
Once the pre-trainedlayers have been imported, excluding the "top" of the model, we can take 1 of 2 Transfer Learning approaches.
1. Feature Extraction Approach
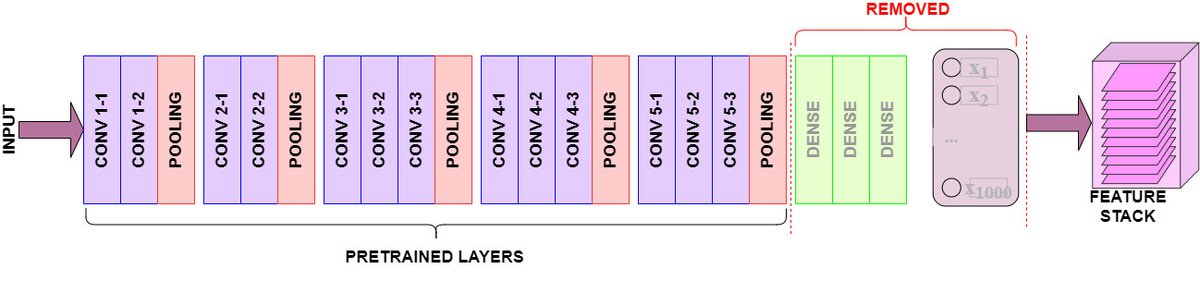
We use the pre-trained model's architecture to create a new dataset from our input images in this approach. We'll import the Convolutional and Pooling layers but leave out the "top portion" of the model (the Fully-Connected layer).
Recall that our example model, VGG16, has been trained on millions of images - including vehicle images. Its convolutional layers and trained weights can detect generic features such as edges, colors, wheels, windshields, etc.
We'll pass our images through VGG16's convolutional layers, which will output a Feature Stack of the detected visual features. From here, it's easy to flatten the 3-Dimensional feature stack into a NumPy array - ready for whatever modeling you'd prefer to conduct.
We can do feature extraction in the following manner:
- Download the pre-trained model. Ensure that the "top" portion of the model - the Fully-Connected layer - is not included.
- Pass the image data through the pre-trained layers to extract convolved visual features
- The outputted feature stack will be 3-Dimensional, and for it to be used for prediction by other machine learning classifiers, it will need to be flattened.
- At this point, you have two options:
- Stand-Alone Extractor: In this scenario, you can use the pre-trained layers to extract image features once. The extracted features would then create a new dataset that doesn't require any image processing.
- Bootstrap Extractor: Write your own Fully-Connected layer, and integrate it with the pre-trained layers. In this sense, you are bootstrapping your own "top model" onto the pre-trained layers. Initialize this Fully-Connected layer with random weights, which will update via backpropagation during training.
This article will show how to implement a "bootstrapped" extraction of image data with the VGG16 CNN. Pre-trained layers will convolve the image data according to ImageNet weights. We will bootstrap a Fully-Connected layer to generate predictions.
2. Fine-Tuning Approach
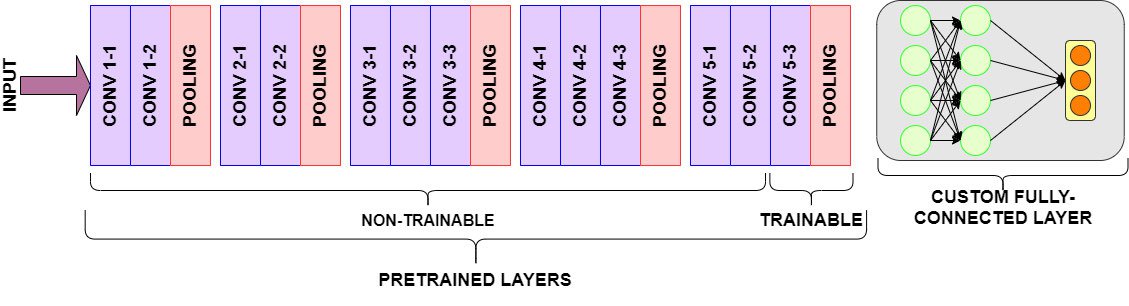
In this approach, we employ a strategy called Fine-Tuning. The goal of fine-tuning is to allow a portion of the pre-trained layers to retrain.
In the previous approach, we used the pre-trained layers of VGG16 to extract features. We passed our image dataset through the convolutional layers and weights, outputting the transformed visual features. There was no actual training on these pre-trained layers.
Fine-tuning a Pre-trained Model entails:
- Bootstrapping a new "top" portion of the model (i.e., Fully-Connected and Output layers)
- Freezing pre-trained convolutional layers
- Un-freezing the last few pre-trained layers training.
The frozen pre-trained layers will convolve visual features as usual. The non-frozen (i.e., the 'trainable') pre-trained layers will be trained on our custom dataset and update according to the Fully-Connected layer's predictions.
In this article, we will demonstrate how to implement Fine-tuning on the VGG16 CNN. We will load some of the pre-trained layers as 'trainable', pass image data through the pre-trained layers, and 'fine-tune' the trainable layers alongside our Fully-Connected layer.
Downloading the Dataset
Before we demonstrate either of these approaches, ensure you've downloaded the data for this tutorial.
To access the data used in this tutorial, check out the Image Classification with Keras article. You can find the terminal commands and functions for splitting the data in this section. If you're starting from scratch, make sure to run the split_dataset function after downloading the dataset so that the images are in the correct directories for this tutorial.
Using Transfer Learning for Food Classification
Pre-trained models, such as VGG16, are easily downloaded using the Keras API. We'll go ahead and use VGG16 for the tutorial, but you should explore the other models available! Many of them have been trained on the ImageNet dataset and come with their advantages and disadvantages. You can find a list of the available models here.
We've also imported something called a preprocess_function alongside the VGG16 model. Recall that image data must be normalized before training. Images are composed of 3-Dimensional matrices containing numerical values in a range of [0, 255]. Not all CNNs have the same normalization scheme, however.
The VGG16 model was trained on data wherein pixel values ranged from [0, 255], and the mean pixel values of the dataset are subtracted from each image channel.
Other models have different normalization schemes, details of which are in their documentation. Some models require scaling the numerical values to be between (-1, +1).
Preparing the training and testing data
Let's first import some necessary libraries.
In the previous article, we defined image generators (see here) for our particular use case. Now, we'll need to utilize the VGG16 preprocessing function on our image data.
With our ImageDataGenerator's, we can now flow_from_directory using the same image directory as the last article:
Using Pre-trained Layers for Feature Extraction
In this section, we'll demonstrate how to perform Transfer Learning without fine-tuning the pre-trained layers. Instead, we'll first use pre-trained layers to process our image dataset and extract visual features for prediction. Then we are creating a Fully-connected layer and Output layer for our image dataset. Finally, we will train these layers with backpropagation.
You'll see in the create_model function the different components of our Transfer Learning model:
- On line 13, we assign the stack of pre-trained model layers to the variable
conv_base. Note thatinclude_top=Falseto exclude VGG16's pre-trained Fully-Connected layer. - On lines 18-25, if the arg
fine_tuneis set to 0, all pre-trained layers will be frozen and left un-trainable. Otherwise, the lastnlayers will be made available for training. - On lines 29-30, we set up a new "top" portion of the model by grabbing the
conv_baseoutputs and flattening them. - On lines 31-33, we define the new Fully-Connected layer, which we'll train with backpropagation. We include dropout regularization to reduce over-fitting.
- Line 34 defines the model's output layer, where the total number of outputs is equal to
n_classes.
Here's the create_model function:
Using Pre-trained Layers with Fine-Tuning
Wow! What an improvement from our custom CNN! Integrating VGG16's pre-trained layers with an initialized Fully-Connected layer achieved an accuracy of 73%! But how can we do better?
In this next section, we will re-compile the model but allow for backpropagation to update the last two pre-trained layers.
You'll notice that we compile this Fine-tuning model with a lower learning rate, which will help the Fully-Connected layer "warm-up" and learn robust patterns previously learned before picking apart more minute image details.
Just as before, we'll initialize our Fully-Connected layer and its weights for training.
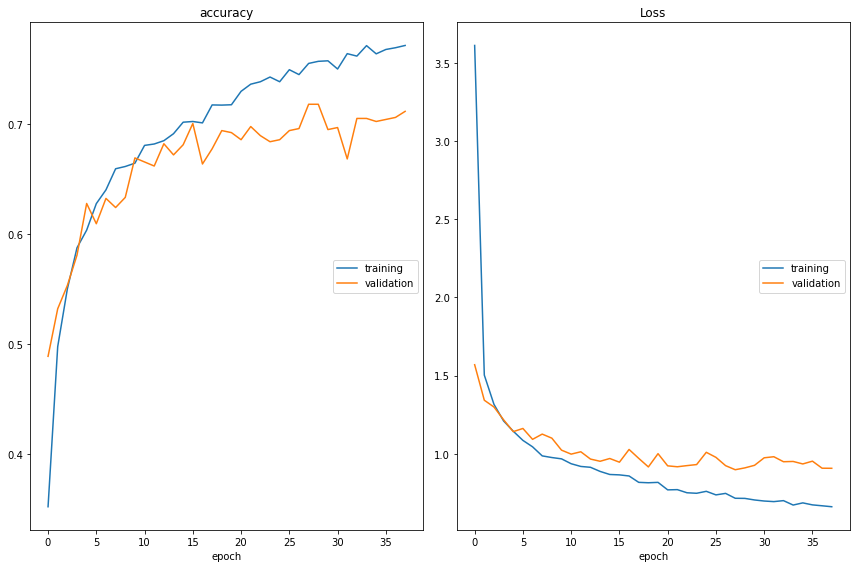
An accuracy of 81%! Amazing what unfreezing the last convolutional layers can do for model performance. Let's get a better idea of how our different models have performed in classifying the data.
Improvements
Recall that our Custom CNN accuracies, Transfer Learning Model with Feature Extraction, and Fine-Tuned Transfer Learning Model are 58%, 73%, and 81%, respectively.
We could see improved performance on our dataset as we introduce fine-tuning. Selecting the appropriate number of layers to unfreeze can require careful experimentation.
Other parameters to consider when training your network include:
- Optimizers: in this article, we used the Adam optimizer to update our weights during training. When training your network, you should experiment with other optimizers and their learning rate.
- Dropout: recall that Dropout is a form of regularization to prevent overfitting of the network. We introduced a single dropout layer in our Fully-Connected layer to constrain the network from over-learning certain features.
- Fully-Connected Layer: if you are taking a bootstrapped approach to Transfer Learning, ensure that your Fully-Connected layer is structured appropriately for the classification task. Is the number of input nodes correct for the outputted features? Do we have too many densely-connected layers?
Summary
In this article, we solved an image classification problem using a custom dataset using Transfer Learning. We saw that by employing various Transfer Learning strategies such as Fine-Tuning, we can generate a model that outperforms a custom-written CNN. Some key takeaways:
- Transfer learning can be a great starting point for training a model when you do not possess a large amount of data.
- Transfer learning requires that a model has been pre-trained on a robust source task which can be easily adapted to solve a smaller target task.
- Transfer learning is easily accessible through the Keras API. You can find available pre-trained models here.
- Fine-Tuning a portion of pre-trained layers can boost model performance significantly.




No comments
If you have any doubts, Please let me know