
Pandas Library

- There are often multiple ways to complete common tasks
- There are over 240 DataFrame attributes and methods
- There are several methods that are aliases (reference the same exact underlying code) of each other
- There are several methods that have nearly identical functionality
- There are many tutorials written by different people that show different ways to do the same thing
- There is no official document with guidelines on how to idiomatically complete common tasks
- The official documentation, itself contains non-idiomatic code
Selecting a Single Column of Data
Selecting a single column of data from a Pandas DataFrame is just about the simplest task you can do and unfortunately, it is here where we first encounter the multiple-choice option that Pandas presents to its users.
You may select a single column as a Series with either the brackets or dot notation. Let’s read in a small, trivial DataFrame and select a column using both methods.
>>> import pandas as pd
>>> df = pd.read_csv('data/sample_data.csv')
>>> df

Selection with the brackets
Placing a column name in the brackets appended to a DataFrame selects a single column of a DataFrame as a Series.
>>> df['state']name
Jane NY
Niko TX
Aaron FL
Penelope AL
Dean AK
Christina TX
Cornelia TX
Name: state, dtype: object
Selection with dot notation
Alternatively, you may select a single column with dot notation. Simply, place the name of the column after the dot operator. The output is the exact same as above.
>>> df.stateIssues with the dot notation
There are three issues with using dot notation. It doesn’t work in the following situations:
- When there are spaces in the column name
- When the column name is the same as a DataFrame method
- When the column name is a variable
You can only use the brackets to select columns with spaces.
df['favorite food']The column name is the same as a DataFrame method
When a column name and a DataFrame method collide, Pandas will always reference the method and not the column name. For instance, the column namecount is a method and will be referenced when using dot notation. This actually doesn’t produce an error as Python allows you to reference methods without calling them. Let’s reference this method now.
df.count

The output is going to be very confusing if you haven’t encountered it before. Notice at the top it states ‘bound method DataFrame.count of’. Python is telling us that this is a method of some DataFrame object. Instead of using the method name, it outputs its official string representation. Many people believe that they’ve produced some kind of analysis with this result. This isn’t true and almost nothing has happened. A reference to the method that outputs the object’s representation has been produced.
The column name is a variable
Let’s say you are using a variable to hold a reference to the column name you would like to select. In this case, the only possibility again is to use the brackets. Below is a simple example where we assign the value of a column name to a variable and then pass this variable to the brackets.
>>> col = 'height'
>>> df[col]Selection with at and iat
Two additional indexers, at and iat, exist that select a single cell of a DataFrame. These provide a slight performance advantage over their analogous loc and ilocindexers. But, they introduce the additional burden of having to remember what they do. Also, for most data analyses, the increase in performance isn’t useful unless it’s being done at scale. And if performance truly is an issue, then taking your data out of a DataFrame and into a NumPy array will give you a large performance gain.
Performance comparison iloc vs iat vs NumPy
Let’s compare the perfomance of selecting a single cell with iloc, iat and a NumPy array. Here we create a NumPy array with 100k rows and 5 columns containing random data. We then create a DataFrame out of it and make the selections.
>>> import numpy as np
>>> a = np.random.rand(10 ** 5, 5)
>>> df1 = pd.DataFrame(a)>>> row = 50000
>>> col = 3>>> %timeit df1.iloc[row, col]
13.8 µs ± 3.36 µs per loop>>> %timeit df1.iat[row, col]
7.36 µs ± 927 ns per loop>>> %timeit a[row, col]
232 ns ± 8.72 ns per loop
While iat is a little less than twice as fast asiloc, selection with a NumPy array is about 60x as fast. So, if you really had an application that had performance requirements, you should be using NumPy directly and not Pandas.
Guidance: Use NumPy arrays if your application relies on performance for selecting a single cell of data and not at or iat.
>>> college = pd.read_csv('data/college.csv')
>>> college.head()

>>> college2 = pd.read_table('data/college.csv', delimiter=',')
>>> college.equals(college2)
Trueread_table is getting deprecated
I made a post in the Pandas Github repo suggesting that a few functions and methods that I’d like to see deprecated. The read_table function is getting deprecated and should never be used.
Guidance: Only use read_csv to read in delimitted text files
isna vs isnull and notna vs notnull
The isna and isnull methods both determine whether each value in the DataFrame is missing or not. The result will always be a DataFrame (or Series) of all boolean values.
These methods are exactly the same. We say that one is an alias of the other. There is no need for both of them in the library. The isna method was added more recently because the characters na are found in other missing value methods such as dropna and fillna. Confusingly, Pandas uses NaN, None, and NaT as missing value representations and not NA.
notna and notnull are aliases of each other as well and simply return the opposite of isna. There's no need for both of them.
Let’s verify that isna and isnull are aliases.
>>> college_isna = college.isna()
>>> college_isnull = college.isnull()
>>> college_isna.equals(college_isnull)
TrueI only use isna and notna
I use the methods that end in na to match the names of the other missing value methods dropna and fillna.
You can also avoid ever using notna since Pandas provides the inversion operator, ~ to invert boolean DataFrames.
Guidance: Use only isna and notna
Arithmetic and Comparison Operators and their Corresponding Methods
All arithmetic operators have corresponding methods that function similarly.
+-add--subandsubtract*-mulandmultiply/-div,divideandtruediv**-pow//-floordiv%-mod
All the comparison operators also have corresponding methods.
>-gt<-lt>=-ge<=-le==-eq!=-ne
Builtin Python functions vs Pandas methods with the same name
There are a few DataFrame/Series methods that return the same result as a builtin Python function with the same name. They are:
summinmaxabs
Let’s verify that they give the same result by testing them out on a single column of data. We begin by selecting the non-missing values of the undergraduate student population column, ugds.
>>> ugds = college['ugds'].dropna()
>>> ugds.head()0 4206.0
1 11383.0
2 291.0
3 5451.0
4 4811.0
Name: ugds, dtype: float64
Verifying sum
>>> sum(ugds)
16200904.0>>> ugds.sum()
16200904.0
Verifying max
>>> max(ugds)
151558.0>>> ugds.max()
151558.0
Verifying min
>>> min(ugds)
0.0>>> ugds.min()
0.0
Verifying abs
>>> abs(ugds).head()0 4206.0
1 11383.0
2 291.0
3 5451.0
4 4811.0
Name: ugds, dtype: float64>>> ugds.abs().head()0 4206.0
1 11383.0
2 291.0
3 5451.0
4 4811.0
Name: ugds, dtype: float64
Time the performance of each
Let’s see if there is a performance difference between each method.
sum performance
>>> %timeit sum(ugds)
644 µs ± 80.3 µs per loop>>> %timeit -n 5 ugds.sum()
164 µs ± 81 µs per loop
max performance
>>> %timeit -n 5 max(ugds)
717 µs ± 46.5 µs per loop>>> %timeit -n 5 ugds.max()
172 µs ± 81.9 µs per loop
min performance
>>> %timeit -n 5 min(ugds)
705 µs ± 33.6 µs per loop>>> %timeit -n 5 ugds.min()
151 µs ± 64 µs per loop
abs performance
>>> %timeit -n 5 abs(ugds)
138 µs ± 32.6 µs per loop>>> %timeit -n 5 ugds.abs()
128 µs ± 12.2 µs per loop
Guidance: Use the Pandas method over any built-in Python function with the same name.
Standardizing groupby Aggregation
There are a number of syntaxes that get used for the groupby method when performing an aggregation. I suggest choosing a single syntax so that all of your code looks the same.
The three components of groupby aggregation
Typically, when calling the groupby method, you will be performing an aggregation. This is the by far the most common scenario. When you are performing an aggregation during a groupby, there will always be three components.
- Grouping column — Unique values form independent groups
- Aggregating column — Column whose values will get aggregated. Usually numeric
- Aggregating function — How the values will get aggregated (sum, min, max, mean, median, etc…)
My syntax of choice for groupby
There are a few different syntaxes that Pandas allows to perform a groupby aggregation. The following is the one I use.
df.groupby('grouping column').agg({'aggregating column': 'aggregating function'})
A buffet of groupby syntaxes for finding the maximum math SAT score per state
Below, we will cover several different syntaxes that return the same (or similar) result for finding the maximum SAT score per state. Let’s look at the data we will be using first.
>>> college[['stabbr', 'satmtmid', 'satvrmid', 'ugds']].head()

Method 1: Here is my preferred way of doing the groupby aggregation. It handles complex cases.
>>> college.groupby('stabbr').agg({'satmtmid': 'max'}).head()

Method 2a: The aggregating column can be selected within brackets following the call to groupby. Notice that a Series is returned here and not a DataFrame.
>>> college.groupby('stabbr')['satmtmid'].agg('max').head()stabbr
AK 503.0
AL 590.0
AR 600.0
AS NaN
AZ 580.0
Name: satmtmid, dtype: float64
Method 2b: The aggregate method is an alias for agg and can also be used. This returns the same Series as above.
>>> college.groupby('stabbr')['satmtmid'].aggregate('max').head()Method 3: You can call the aggregating method directly without calling agg. This returns the same Series as above.
>>> college.groupby('stabbr')['satmtmid'].max().head()Major benefits of preferred syntax
The reason I choose this syntax is that it can handle more complex grouping problems. For instance, if we wanted to find the max and min of the math and verbal sat scores along with the average undergrad population per state we would do the following.
>>> df.groupby('stabbr').agg({'satmtmid': ['min', 'max'],
'satvrmid': ['min', 'max'],
'ugds': 'mean'}).round(0).head(10)
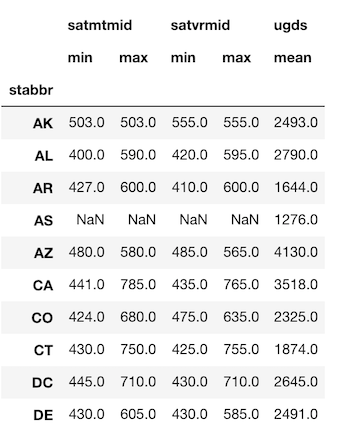
This problem isn’t solvable using the other syntaxes.
Guidance — Use df.groupby('grouping column').agg({'aggregating column': 'aggregating function'}) as your primary syntax of choice
Best of the API
The Pandas DataFrame API is enormous. There are dozens of methods that have little to no use or are aliases. Below is my list of all the DataFrame attributes and methods that I consider sufficient to complete nearly any task.
Attributes
- columns
- dtypes
- index
- shape
- T
- values
Aggregation Methods
- all
- any
- count
- describe
- idxmax
- idxmin
- max
- mean
- median
- min
- mode
- nunique
- sum
- std
- var
Non-Aggretaion Statistical Methods
- abs
- clip
- corr
- cov
- cummax
- cummin
- cumprod
- cumsum
- diff
- nlargest
- nsmallest
- pct_change
- prod
- quantile
- rank
- round
Subset Selection
- head
- iloc
- loc
- tail
Missing Value Handling
- dropna
- fillna
- interpolate
- isna
- notna
Grouping
- expanding
- groupby
- pivot_table
- resample
- rolling
Joining Data
- append
- merge
Other
- asfreq
- astype
- copy
- drop
- drop_duplicates
- equals
- isin
- melt
- plot
- rename
- replace
- reset_index
- sample
- select_dtypes
- shift
- sort_index
- sort_values
- to_csv
- to_json
- to_sql
Functions
- pd.concat
- pd.crosstab
- pd.cut
- pd.qcut
- pd.read_csv
- pd.read_json
- pd.read_sql
- pd.to_datetime
- pd.to_timedelta






No comments
If you have any doubts, Please let me know